I'm currently working on a project that requires splitting sentences in order to compare two words (a given word which the user needs to type, giving us the second) to each other, and check the accuracy of the user's typing. I've been using x.split(" ") to do this, however, this is causing me an issue.
Let's say the given sentence was The quick brown fox, and the user types in The quick brown fox.
Instead of returning ['The','quick ', 'brown', 'fox'], it's returning ['The', 'quick', '', 'brown', fox']. This makes it harder to check for accuracy, as I'd like it to be checked word per word.
In other words, I'd like to append any extra spaces to the word that came before, but the split function is creating separate (empty) elements instead. How do I go about removing any empty entries and adding them to the word that came before them?
I'd like this to work for lists where there are multiple '' entries in a row as well, such as ['The', 'quick', '', '', 'brown', fox'].
Thanks!
EDIT - The code I'm using to test this is just some variation of x = The quick brown fox".split(' '), with different whitespaces.
EDIT 2 - I didn't think about this (thanks Malonge), but if the sentence starts with a space, I would actually like that to be counted as well. I don't know how easy that would be, since I'd need to make this particular instance an exception where the whitespace needs to be appended to the word that follows rather than the one that precedes it. However, I'll make a conscious choice to ignore that scenario when calculating accuracy due to the difficulty in implementing it.
 asked Dec 11 '25 18:12
asked Dec 11 '25 18:12
You can use regex for this, this will match all the spaces that come after the first space:
>>> import re
>>> s = "The quick brown fox"
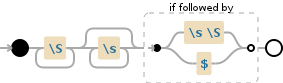
>>> re.findall(r'\S+\s*(?=\s\S|$)', s)
['The', 'quick ', 'brown', 'fox']
Debuggex Demo:
\S+\s*(?=\s\S|$)
Update:
To match leading spaces at the start of the string some modification to the above regex are required:
>>> s = "The quick brown fox"
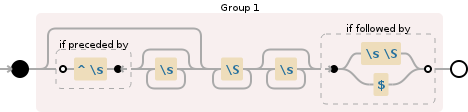
>>> re.findall(r'((?:(?<=^\s)\s*)?\S+\s*(?=\s\S|$))', s)
['The', 'quick ', 'brown', 'fox']
>>> s1 = " The quick brown fox"
>>> re.findall(r'((?:(?<=^\s)\s*)?\S+\s*(?=\s\S|$))', s1)
[' The', 'quick ', 'brown', 'fox']
Debuggex Demo:
((?:(?<=^\s)\s*)?\S+\s*(?=\s\S|$))
You can get there a number of ways, but perhaps the easiest with what you've demonstrated is just to split without specifying a split parameter, which makes it split on whitespace, not just a single space:
>>> s = "The quick brown fox"
>>>
>>> s.split(' ')
['The', 'quick', '', 'brown', 'fox']
>>> s.split()
['The', 'quick', 'brown', 'fox']
You could also get there with:
>>> words = [w for w in s.split(" ") if w]
>>> words
['The', 'quick', 'brown', 'fox']
Or using regex:
>>> import re
>>>
>>> re.split('\s*', s)
['The', 'quick', 'brown', 'fox']
If you love us? You can donate to us via Paypal or buy me a coffee so we can maintain and grow! Thank you!
Donate Us With

